Первые впечатления от нейросети GPT-4V (ision)

25 сентября 2023 года OpenAI объявила о запуске двух новых функций, которые расширяют возможности взаимодействия людей с ее последней и самой продвинутой моделью GPT-4: возможность задавать вопросы о изображениях и использовать речь как входные данные для запроса.
Эта функциональность означает, что GPT-4 двигается в сторону мультимодельных моделей. Это означает, что модель может принимать несколько «модальностей» ввода — текст и изображения — и возвращать результаты на основе этих входных данных. Bing Chat, разработанный Microsoft в партнерстве с OpenAI, и модель Google Bard также поддерживают изображения как входные данные.
В этом руководстве мы поделимся нашими первыми впечатлениями от функции ввода изображения GPT-4V. Мы проведем ряд экспериментов, чтобы проверить функциональность GPT-4V, показать, где модель проявляет себя хорошо, и где испытывает трудности.
Итак, приступим!
Что такое GPT-4V?
GPT-4V(ision) (GPT-4V) — это мультимодель, разработанная OpenAI. GPT-4V позволяет пользователю загрузить изображение в качестве входных данных и задать вопрос о изображении, задачу, известную как визуальное вопросно-ответное взаимодействие (VQA).
GPT-4V запускается с 24 сентября и будет доступен как в мобильном приложении OpenAI ChatGPT для iOS, так и в веб-интерфейсе. Для использования этого инструмента вам необходима подписка на GPT-4.
Давайте проведем эксперименты с GPT-4V и проверим его возможности!
Тест #1: Визуальное вопросно-ответное взаимодействие
Один из наших первых экспериментов с GPT-4V был связан с запросом о меме по компьютерному зрению. Мы выбрали этот эксперимент, потому что он позволяет нам определить, насколько GPT-4V понимает контекст и взаимосвязь в данном изображении.
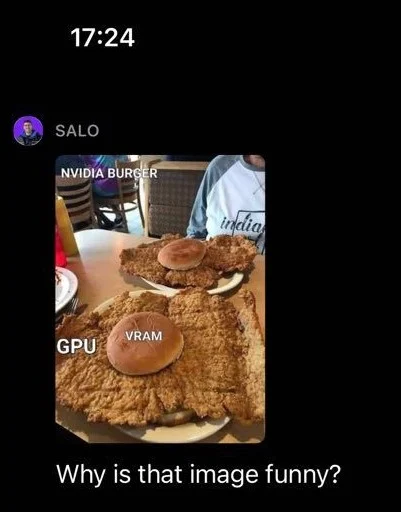
GPT-4V успешно описал, почему изображение смешное, ссылаясь на различные компоненты изображения и их взаимосвязь. Следует отметить, что предоставленный мем содержал текст, который GPT-4V смог прочитать и использовать для создания ответа. Однако GPT-4V сделал ошибку. Модель сказала, что жареная курка называется «NVIDIA BURGER», а не «GPU».
Затем мы перешли к тестированию GPT-4V с валютой, проведя несколько разных тестов. Сначала мы загрузили фотографию американского цента. GPT-4V успешно определил происхождение и номинал монеты:

Затем мы загрузили изображение с несколькими монетами и подсказали GPT-4V следующим текстом: «Сколько у меня денег?»

GPT-4V смог определить количество монет, но не распознал тип валюты. С последующим вопросом GPT-4V успешно идентифицировал тип валюты:
Переходя к другой теме, мы решили попробовать использовать GPT-4V с фотографией из популярного фильма: «Криминальное чтиво». Мы хотели узнать: сможет ли GPT-4 ответить на вопрос о фильме, не получив информацию в текстовой форме, о каком фильме идет речь?
Мы загрузили фотографию из фильма «Криминальное чтиво» с запросом «Хороший ли это фильм?», на что GPT-4V ответил описанием фильма и ответом на наш вопрос. GPT-4V предоставил общее описание фильма и краткое изложение характеристик фильма, считающихся положительными и отрицательными.
Затем мы спросили о рейтинге IMDB для фильма, на что GPT-4V ответил рейтингом на январь 2022 года. Это указывает на то, что, как и другие модели GPT, выпущенные OpenAI, существует ограничение в знаниях, после которого у модели нет более свежей информации.
Затем мы исследовали способности GPT-4V к ответам на вопросы о местоположении. Мы загрузили фотографию Сан-Франциско с текстовым запросом: «Где это?». GPT-4V успешно идентифицировал местоположение, Сан-Франциско, и отметил, что Трансамериканская пирамида, изображенная на нашей фотографии, является знаковой достопримечательностью города.

Переходя к растениям, мы предоставили GPT-4V фотографию мирацета и задали вопрос: «Что это за растение и как о нем заботиться?»

Модель успешно определила, что это мирацет, и дала советы по уходу за растением. Это иллюстрирует удобство сочетания текста и изображения в GPT-4V для создания мультимодальных моделей. Модель дала грамотный ответ на наш вопрос, не требуя создания двухэтапного процесса (например, классификация для определения растения, а затем GPT-4 для предоставления советов по уходу за ним).
Тест #2: Оптическое распознавание символов (OCR)
Мы провели два теста, чтобы изучить возможности GPT-4V в области OCR: OCR на изображении с текстом на шине автомобиля и OCR на фотографии абзаца из цифрового документа. Наша цель — понять, как GPT-4V справляется с OCR в реальных условиях, где текст может иметь меньший контраст и находиться под углом, в отличие от цифровых документов с четким текстом.

GPT-4V не смог правильно идентифицировать серийный номер на изображении шины. Несколько чисел были правильными, но в результатах модели было несколько ошибок.
В нашем тесте с документом мы представили текст с веб-страницы и попросили GPT-4V прочитать текст на изображении. Модель смогла успешно определить текст на изображении.

GPT-4V отлично справляется с переводом слов на изображении в отдельные символы в тексте. Это полезное наблюдение для задач, связанных с извлечением текста из документов.
Тест #3: OCR для математики
OCR для математики — это специализированная форма OCR, относящаяся специально к математическим уравнениям. OCR для математики часто считается самостоятельной дисциплиной, потому что синтаксис того, что должна распознать модель OCR, распространяется на широкий спектр символов.
Мы представили GPT-4V математический вопрос. Этот математический вопрос был сделан в скриншоте из документа. Вопрос заключался в вычислении длины троса спуска по заданным углам. Мы представили изображение с запросом «Решите это.»

Модель определила, что задачу можно решить с помощью тригонометрии, определила функцию для использования и предоставила пошаговое описание того, как решить задачу. Затем GPT-4V предоставил правильный ответ на вопрос.
Тем не менее в системной карточке GPT-4V отмечается, что
модель может упустить математические символы. Разные тесты, включая тесты, где уравнение или выражение написано от руки на бумаге, могут указать на недостатки модели в способности отвечать на вопросы по математике.
Тест #4: Обнаружение объектов
Обнаружение объектов — это фундаментальная задача в области компьютерного зрения. Мы попросили GPT-4V определить положение различных объектов, чтобы оценить его способность выполнять задачи по обнаружению объектов.
В нашем первом тесте мы попросили GPT-4V обнаружить собаку на изображении и предоставить значения x_min, y_min, x_max и y_max, связанные с положением собаки. Координаты ограничивающего прямоугольника, возвращенные GPT-4V, не соответствовали положению собаки.

Хотя способности GPT-4V к ответам на вопросы об изображении могут быть мощными, модель не является заменой тщательно настроенных моделей обнаружения объектов в ситуациях, где вам нужно знать, где находится объект на изображении.
Тест #5: CAPTCHA
Мы решили протестировать GPT-4V с CAPTCHA, задачей, которую OpenAI изучала в своих исследованиях и описала в системной карточке. Мы обнаружили, что GPT-4V способен определить, что изображение содержит CAPTCHA, но часто не проходил тесты. В примере с светофором GPT-4V пропустил некоторые рамки, содержащие светофоры.
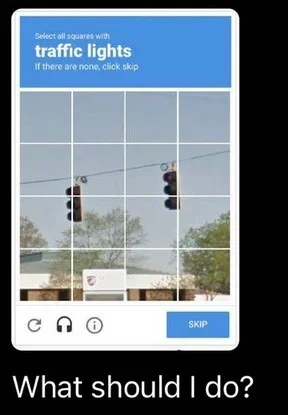
В следующем примере с пешеходным переходом GPT-4V правильно классифицировал несколько рамок, но неправильно классифицировал одну рамку в CAPTCHA.
Тест #6: Кроссворды и Судоку
Мы решили проверить, как GPT-4V справляется с кроссвордами и судоку.
Сначала мы запросили GPT-4V фотографии кроссворда с текстовой инструкцией «Решите это.» GPT-4V определил, что на изображении находится кроссворд и попытался предоставить решение. Модель, казалось, правильно прочла подсказки, но неправильно интерпретировала структуру доски. В результате предоставленные ответы были неверными.
Это же ограничение проявилось и в нашем тесте с судоку, где GPT-4V определил игру, но неправильно понял структуру доски и, следовательно, вернул неточные результаты:
Ограничения и безопасность GPT-4V
OpenAI провела исследования с альфа-версией модели для зрения, доступной ограниченной группе пользователей, как описано в официальной системной карточке GPT-4V(ision). В ходе этого процесса была собрана обратная связь и получены знания о том, как GPT-4V работает с запросами, предоставленными разными людьми. Это было дополнено «красной командой», в которой внешние эксперты «квалифицированно оценивали ограничения и риски, связанные с моделью и системой».
На основе исследований OpenAI в системной карточке GPT-4V указывается множество ограничений модели, таких как:
Отсутствие текста или символов на изображении
Отсутствие математических символов
Невозможность распознавания пространственных местоположений и цветовПомимо ограничений OpenAI выявила, исследовала и попыталась смягчить несколько рисков, связанных с моделью. Например, GPT-4V избегает идентификации конкретного человека на изображении и не отвечает на запросы, касающиеся символов ненависти.
Тем не менее, существует еще работа по обеспечению безопасности модели. Например, в системной карточке модели указывается, что «по запросу GPT-4V может генерировать контент, хвалящий определенные малоизвестные группы ненависти в ответ на их символы».
GPT-4V для компьютерного зрения и не только
GPT-4V представляет собой значительное событие в области машинного обучения и обработки естественного языка. С GPT-4V вы можете задавать вопросы о изображении — и последующие вопросы — на естественном языке, и модель будет пытаться ответить на ваш вопрос.
GPT-4V хорошо справилась с различными общими вопросами об изображении и продемонстрировала понимание контекста в некоторых тестовых изображениях. Например, GPT-4V успешно отвечала на вопросы о фильме, изображенном на фотографии, не получая информации в текстовой форме о фильме.
Для общих вопросов и ответов GPT-4V представляет интерес. В то время как в прошлом существовали модели для этой цели, они часто были не очень гладкими в ответах. GPT-4V способен отвечать и на вопросы и на последующие вопросы об изображении и делать это детально.
С GPT-4V вы можете задавать вопросы об изображении, не создавая двухэтапного процесса (например, классификация, а затем использование результатов для задания вопроса модели на языке GPT). Вероятно, существуют ограничения в том, что GPT-4V может понимать, поэтому тестирование сценария использования для понимания того, как модель работает, является важным.
Тем не менее у GPT-4V есть свои ограничения. Модель «галлюцинирует», возвращая неточную информацию. Это риск при использовании языковых моделей для ответов на вопросы. Кроме того, модель не смогла точно вернуть ограничивающие рамки для обнаружения объектов, что свидетельствует о том, что в настоящее время она не подходит для этого сценария использования.
Мы также заметили, что GPT-4V не может отвечать на вопросы о людях. Предоставив фотографию Тейлор Свифт и спросив, кто изображен на фотографии, модель отказалась отвечать. OpenAI определяет это как ожидаемое поведение в опубликованной системной карточке модели.